
Edge Computing – (K)eine Randerscheinung
0
Immer öfter wird der Begriff „Edge Computing“ als neuer Trend in der IT propagiert. Eine kleine Artikelserie soll klären, was sich dahinter verbirgt und warum es sich tatsächlich lohnt, sich damit auseinanderzusetzen.
Der englische Begriff „Edge“ steht für Kante oder Rand. Im Fall von Edge Computing ist damit nicht die Verwendung der allerneuesten Technik gemeint („Cutting Edge“), sondern er bezieht sich auf den „Rand“ der IT-Infrastruktur. Edge Computing bedeutet also nichts anderes, als dass die Verarbeitung von Daten ungefähr dort erfolgt, wo diese entstehen. Das hört sich erst einmal nicht anders an als althergebrachte IT-Konzepte wie Desktop-PCs oder Workstations, lokale Server oder kleine Rechenzentren vor Ort. Der Unterschied zur IT der 90er oder 2000er Jahre besteht aber darin, dass Cloud-Technologien und Service-orientierte Infrastrukturen inzwischen allgegenwärtig sind. Dabei wächst der Druck vieler Anbieter, die Workloads ihrer Kunden in die Cloud zu bekommen.
Edge Computing ist dafür sowohl Ergänzung als auch Gegenbewegung. Es lässt sich mit lokaler Datenverarbeitung im Cloud-Zeitalter übersetzen oder einfach: „lokale IT, bei Bedarf mit der Cloud verknüpft“. Edge Computing ist deshalb eher eine Denkweise als eine scharf definierte Architektur oder Technologie. Es braucht sowohl auf der Software-Seite als auch bei der Hardware keine grundsätzlich andersartigen Geräte, Protokolle oder Software-Schichten.
Die Cloud löst nicht alle Probleme
Trotzdem unterscheidet Edge Computing sich in mehreren Punkten von traditioneller Vor-Ort-Datenverarbeitung, denn die Anforderungen an die IT haben sich entscheidend verändert. So werden immer mehr Daten von Sensoren, Kameras und anderen Geräten ohne direktes menschliches Zutun erzeugt und von Steuerungen oder KI-Systemen ebenso autonom und oft in Echtzeit ausgewertet. Der Transport solcher Daten in die Cloud bringt in vielen Fällen Nachteile mit sich. Deshalb ist Edge Computing vor allem bei der Digitalisierung der Industrie und beim Internet of Things (IoT) ein wichtiges Thema.
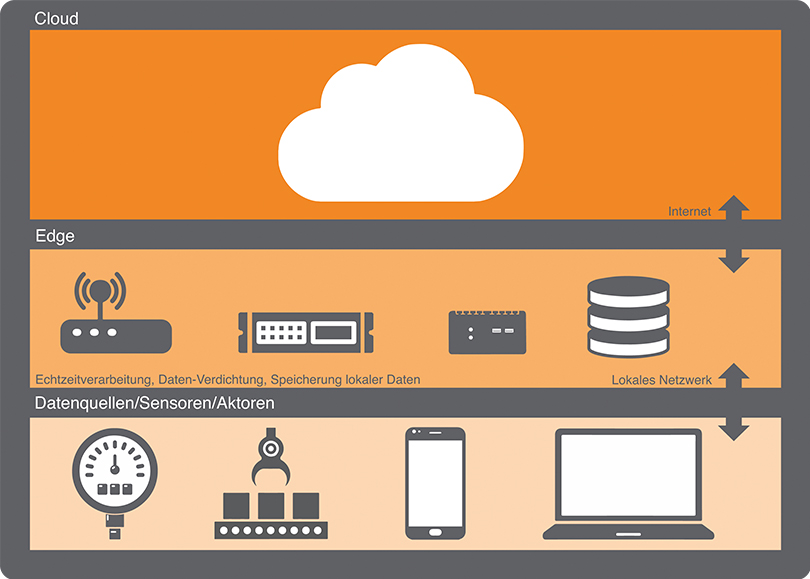
Fünf Gründe für Edge Computing
Gründe dafür, sich nicht komplett auf die Cloud zu verlassen, gibt es viele. Die folgenden fünf sind die wichtigsten:
- Latenzen
- Datenmengen/Bandbreite
- Netzwerk-Verfügbarkeit
- Datensicherheit
- Kosten von Cloud-Diensten
Latenzen, Datenmengen und Bandbreite
Steuerungen in der Industrie, bei der Gebäude-Automatisierung und ganz besonders bei autonomen Fahrzeugen müssen in der Lage sein, große Datenmengen aus verschiedenen Quellen permanent auszuwerten und bei Bedarf in Echtzeit reagieren. Latenzen, also Verzögerungen beim Transport durch diverse Netzwerke in die Cloud und zurück, sind da ein Hindernis. Auch ist es oft unnötig, große Mengen Rohdaten in der Cloud zu lagern beziehungsweise dort zu verarbeiten, Bandbreite steht oft nicht unbegrenzt zur Verfügung oder muss teuer bezahlt werden.
Netzwerk-Verfügbarkeit
Für die Netzwerk-Verfügbarkeit gilt ähnlich wie bei der Latenz, dass ein Edge-Computing-Konzept für Robustheit gegenüber Netzwerk-Ausfällen sorgen kann. Eine komplett redundante Netzwerk-Anbindung würde bedeuten, mindestens zwei verschieden Anbieter über komplett getrennte Leitungen bei gleicher Leistung zu haben. Das ist zumindest in Deutschland nicht überall möglich und bringt außerdem zusätzliche Komplexität mit sich.
Datensicherheit
Ob zu Recht oder nicht, viele Anwender bleiben bei der Speicherung sensibler eigener oder Kundendaten in der Cloud misstrauisch. Eine Edge-Cloud-Kombination kann auch Teil eines Datensicherheits-Konzepts sein und dafür sorgen, dass bestimmte Daten die Speicher des eigenen Unternehmens nicht verlassen.
Kosten von Cloud-Diensten
Zu diesen technisch bedingten vier Punkten kommt noch der Kostenaspekt von Cloud-Diensten, denn diese sind nicht immer günstiger als eine On-Premise-Lösung, vor allem aber oft langfristig nicht kalkulierbar.
Individuelle Anforderungen an Edge Computing
Die Anforderungen für Edge Computing sind sehr individuell. Edge-Rechenzentren beispielsweise für Streaming können Tausende von Rack-Servern umfassen. Am anderen Ende der Skala steht ein einzelner miniaturisierter Ein-Platinen-Rechner, der Sensordaten aufnimmt, verarbeitet und weiterreicht. Zudem werden nur die wenigsten Edge-Projekte auf der grünen Wiese geplant. Besonders in der verarbeitenden Industrie müssen vorhandene Anlagen zur Produktionssteuerung mit der IT verknüpft werden und diese wiederum mit der Cloud.
Dabei gibt es auf allen Ebenen eine Vielzahl unterschiedlicher Protokolle und Interfaces. Die Herausforderung besteht darin, unter diesen Umständen zukunftsfähige, idealerweise extrem flexible, elastische Infrastrukturen aufzubauen, die langfristig die Digitalisierung des Unternehmens unterstützen. Dabei kommen auch auf Hardware-Hersteller neue Aufgaben hinzu, denn mit Servern „von der Stange“ ist das oft nicht machbar.
Im zweiten Teil dieser kleinen Artikel-Serie zu Edge Computing wird es deshalb demnächst speziell um Hardware gehen, vom Edge-Router bis zum Micro-Datacenter.






